How should we evaluate autonomous cyber defence agents in ways that support real human decision-making, trust, and accountability?
Autonomous cyber defence agents promise speed, adaptability, and scale — capabilities that human teams alone cannot achieve. Yet as these systems gain decision authority, a fundamental question emerges:
What does it mean for an autonomous system to be “safe enough”?
Traditionally, evaluation has focused on technical performance — accuracy, reward optimisation, detection rates. But our research suggests this is only part of the story.
Drawing on interviews and workshops with expert practitioners, we found that evaluation is best understood as a socio-technical process shaped by human judgement, organisational context, and accountability structures.
Several patterns were particularly striking.
First, practitioners rarely interpret performance metrics in isolation. Instead, evaluation is relational — dependent on who is using the system, the risks at stake, and the operational environment.
Second, characteristics often treated as separate — robustness, reliability, resilience, interpretability — are experienced as deeply interconnected. Strengthening one can strengthen another or introduce new vulnerabilities elsewhere.
Third, accountability plays a quiet but powerful role. People do not simply ask whether a system works; they ask whether its behaviour can be explained, justified, and ethically governed.
Perhaps most importantly, evaluation is not a moment in time. It is continuous — evolving across the agent’s entire lifecycle from development, through deployment, operation, and adaptation.
Designing for Shared Understanding
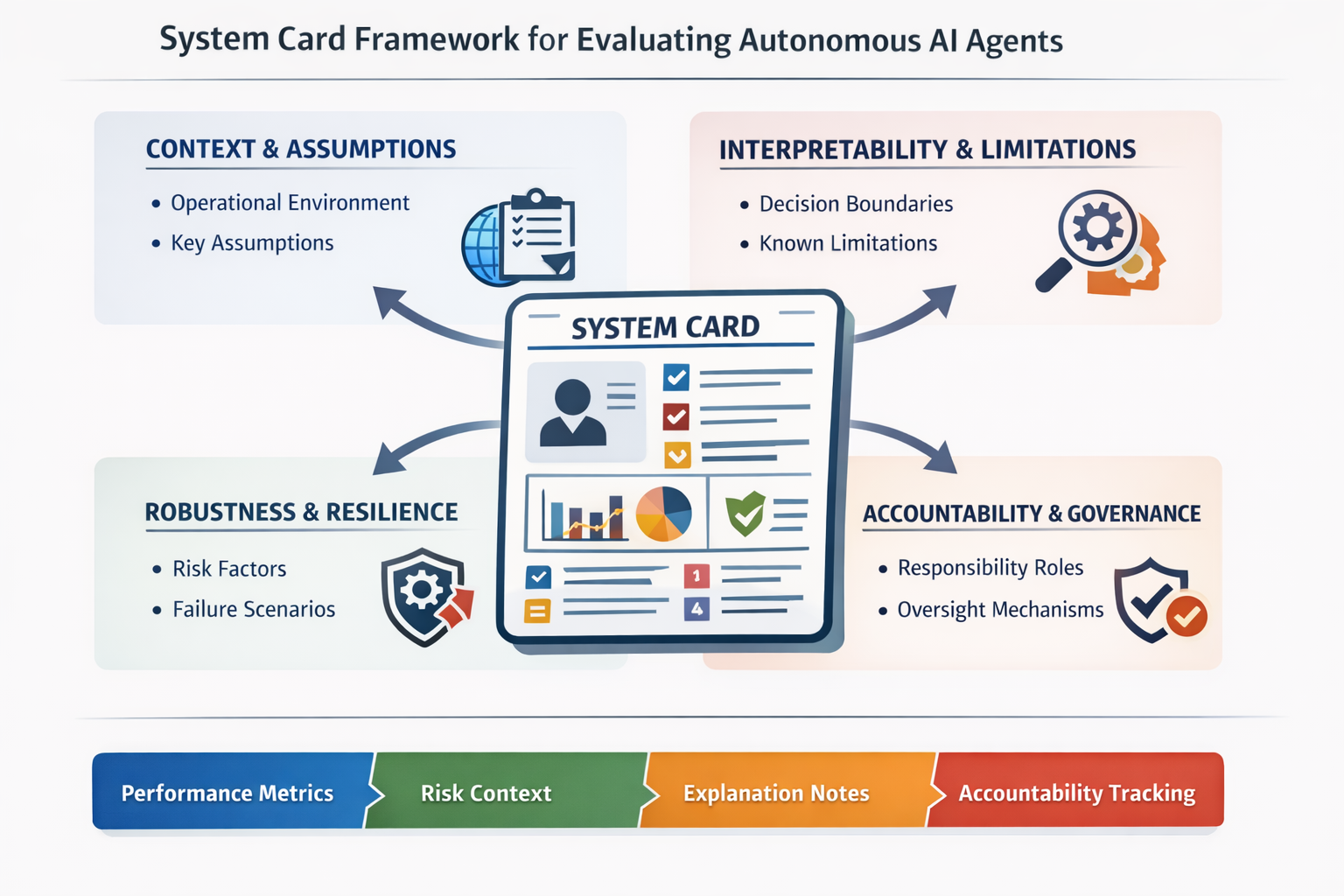
In response, we developed System Cards, a human-centred evaluation artefact intended to support shared understanding of autonomous agents across multiple stakeholders.
System Cards capture technical performance metrics, plus assumptions, limitations, operational boundaries, and mechanisms for oversight. Their purpose is not to replace technical assurance, but to make evaluation meaningful to the people responsible for acting on it.
This is because ultimately, trustworthy AI is not just a technical achievement — it is an organisational and human one.
Later this year, I’ll be presenting this research in collaboration with Tulpa at HCI2026. If you will be attending HCI2026, I hope to see you there.